If you manage a website that is extremely large or a site that contains content which is very regularly updated, it’s important to prioritise the pages you want Google to pay attention to. If Googlebot is just left to crawl and index the site as and when it pleases, it’s extremely likely that Google will attempt to crawl far too many pages at once – which can lead to a number of issues such as multiple parallel connections overwhelming your servers, or Google automatically prioritising unimportant pages whilst ignoring pages that are extremely valuable to you as a business.

As a result, pages within your site that could potentially rank really well in organic Google search results may instead be completely disregarded. For example, Google could easily choose to prioritise a standard About page which is purely informational and doesn’t directly drive conversions, in place of a core product page which has the potential to rank well at the top of Google whilst also directly driving multiple sales on a daily basis.
So… how can we control what Google crawls and indexes and how do we prioritise the pages that are important to your business?
How to control Googlebot’s Crawl Budget and get your web pages indexed
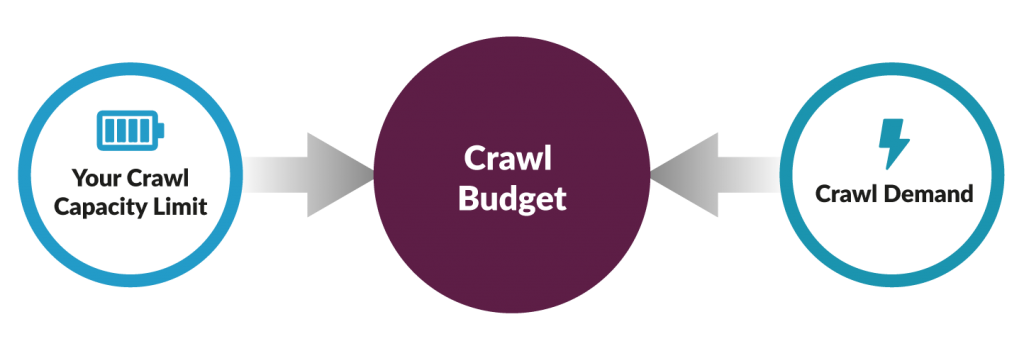
‘Crawl Budget’ is the term used to describe the volume of resources and time that Google devotes to crawling an individual site. This crawl budget is determined by two main factors – your crawl capacity limit (the maximum number of simultaneous connections that Google can use to crawl a site AND the duration of the delay between fetches) and the crawl demand (how important Google deem a crawl of the site to be, depending on the size of the site, it’s popularity, how often it is updated and so on).
Your Crawl Capacity can vary depending on a number of factors, including:
- Crawl Health – If the site is regularly crawled with ease and at a good speed, the crawl health increases and the number of connections / parallel site crawls permitted also increases. If a crawl flags a server error or the site is slow to respond, the number of connections will drop.
- GSC Limits – You can request for Googlebot to reduce their crawling of your website, via Google Search Console.
- Google Crawling Limits – Like any tool or company, Google doesn’t have an infinite supply of resources. This can impact the speed and depth of your website crawls.
Crawl Demand can also vary, depending on the following factors:
- Perceived Inventory – Without any guidance, Google will automatically try and crawl most if not all of your site’s URLs that it knows about. Naturally most sites contain URLs that you don’t necessarily want crawled, some have duplicate URLs and some pages just aren’t targeting organic search traffic. Going through all of the pages (including those that don’t need to be crawled or indexed) wastes a lot of Google’s time. By excluding non important pages from being crawled, you can increase the focus being placed on the pages you do want to rank in search and the speed at which it is done.
- Popularity – Popular URLs that already get a lot of visits online are typically crawled more often than others, as Google knows that they are visited regularly and so need to regularly be refreshed within Google’s index.
- Staleness – Google will try and recrawl URLs frequently enough to pick up on any changes that have been made. Therefore if you don’t regularly update your site content, Google is less likely to recrawl and reindex your pages as they’re not expecting many (if any) changes to have been made.
Notes: Site wide updates such as domain changes or site moves can also trigger an increase in crawl demand, as Google will detect that all of a site’s URLs have been updated and so will need to be reindexed.
So, now that we know what factors impact your crawl budget, how do we help ensure that we maximise your crawling efficiency, using this information? Luckily, Google has also provided a list of Best Practices for this sort of thing.
Best Practices for Googlebot Crawl Budget Management
There are a number of tools and methods that you can use to tell Google which pages within your site are really important to you – those which you really need to rank within organic Google searches. These include:
- Maintain your sitemaps
It’s important that you keep your website sitemaps up to date. Google regularly reads sitemaps that have been submitted to Google Search Console and so it’s important to remove unimportant content from your sitemaps, whilst also ensuring content that you do want indexed has been included. Google Search Central contains a guide on building and submitting a sitemap, should you need it. - Block URLs
Take the URLs within your site that you don’t need crawled and block them from Googlebot. Any pages that you don’t want to appear within organic search results should be excluded from indexing. This can be instructed using your robots.txt file or Google’s URL Parameters tool. - Remove all soft 404s
Soft 404 errors will repeatedly be crawled, despite returning an error code. These repeated crawls will be using up your crawl budget which would be much better spent elsewhere. You can check the Index Coverage report in Google Search Console to check any soft 404 errors being generated by your website. - Use 404/401s
Return a 404 or 410 error for permanently removed pages. A 404 error (not a soft 404) will indicate to Google that you do not want the page in question to be crawled again. This is arguably better than blocking URLs as blocked URLs will still stay part of a crawl queue for longer than a URL generating a 404 or 401. - Eliminate duplicated content
Consolidate any duplicate content within your website. By eliminating duplicate content, crawlers can instead focus on crawling unique content. - Avoid redirect chains
Redirect chains can have a detrimental impact on crawling – find out more about redirect chains and how they can impact your website.
So now that you understand more about Googlebot’s Crawl Budget and how best to manage it – as well as Google’s Best Practices – what’s next? Aside from the above, it’s also incredibly important to make sure that your pages load efficiently and that you regularly monitor your site crawling.
If you’re interested in how to best monitor your site’s crawling and indexing as well as the key steps Google recommend during this process, you’re in luck – part 2 of this blog, ‘Googlebot Site Crawling and Indexing – 5 Key Steps You Should Know’ is coming soon, so check back regularly for updates.
For now, we will leave you with the information above. Of course if you have any questions regarding this blog or would like experienced SEO professionals to take a look at your website on your behalf, the Technical SEO team here at Varn would love to hear from you. Simply drop us an email at [email protected] or give us a call on 01225 439960. We look forward to hearing from you.


